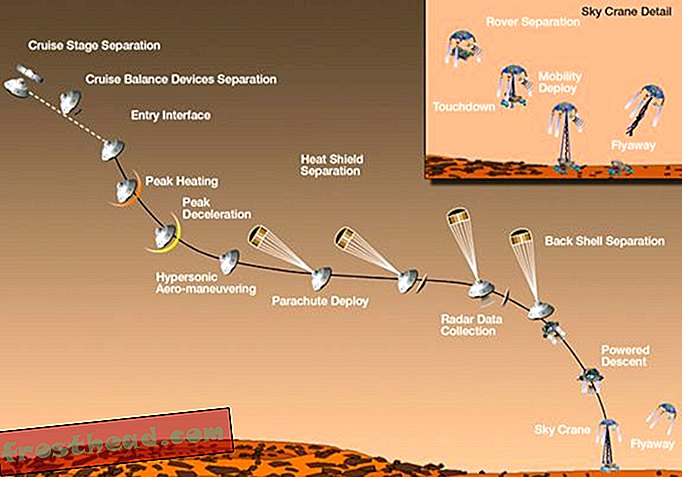
IBMのWatsonスーパーコンピューターが先週Jeopardyを演じる2人の人間を振り回しているのを見ましたか? いや? 私でもない。 そして、私が覚えているよりも多くの情報を含み、人間よりも速く反射する発明に脅されることを拒否するだけではありません。 ご存知のように、最近のアメリカ科学振興協会会議でのセッションで私が思い出したように、コンピューターは科学を含むいくつかのことに苦手です。
科学の発見は、銀河の写真の中の奇妙な緑の雲のようなデータの一部を見つけて、「それは面白い」と言うことにしばしば依存します。 コンピューターはそれを行うのが得意ではなく、人間もパターンを視覚的に見つけるのがはるかに優れています。 これにより、たとえば銀河の写真を見て適切に分類する準備が整います。 これが、Sloan Digital Sky Surveyによって撮像されたすべての銀河を識別する必要性から生まれた、最初のGalaxy Zooの誕生です。
その最初のプロジェクトは2007年に1000万個の銀河の分類(および、前述の奇妙な緑の雲であるHanny's Voorwerpを含む多くの奇妙な物質の識別)で終了しました。惑星の検索、月の研究、第一次世界大戦時代のイギリス海軍の船からの気象観測の回復などのタスクを完了します。 しかし、このようなプロジェクトに積極的に参加していない人でさえ、壮大なプロジェクトのヒューマンコンピューターとして採掘されています。
オンラインでフォームに記入し、読みにくい文字や単語の寄せ集めでそのボックスにたどり着くとわかりますか? これはCAPTCHAと呼ばれます。 文字が何を言っているか、または綴っているのかを把握できますが、コンピューターはできません。 これはスパマーのブロックです。 最新の反復はreCAPTCHAと呼ばれ、これらのボックスには2つの単語が含まれます。 気付いていないかもしれませんが、これらの単語をデコードすると、Googleが書籍をデジタル化するのに役立ちます。 Googleは、知っている単語を1つと、デジタル化プログラムが単語としてラベル付けしているが、そのボックスに識別できない2つ目の単語を入力し、両方を尋ねます。 毎日2億の単語をデコードすることで、Googleが何百万もの書籍をデジタル化するのを支援してきました。
オックスフォードの天文学者でZooniverseの創設者の1人であるChris Lintottは、まもなくデータの潮流が非常に大きくなり、人間が処理できるものを圧倒することになると指摘しました。 たとえば、大規模なSynoptic Survey望遠鏡が数年でオンラインになると、3日ごとに空をスキャンし、Sloan Digital Sky Surveyが何年もしていたのと同じ量のデータを生成します。 その時点で、機械を訓練するために人間がまだ必要であるとリントットは言った。